Calico 对 k8s 网络的实现
Calico 是 k8s 常用的 cni 插件之一,部署简单而且性能还不错,主要实现的是 pod ip 分配, pod 到 pod 的通信,以及网络策略等。
区分 ip 地址和 mac 地址
在理解 calico 的网络结构之前,先搞清楚在数据传输中 ip 地址和 mac 地址的区别。 如果靠 ip 地址就能确定通信的话那么还要 mac 地址干什么咧?答案就是 ip 地址是个网络层上的东西,靠这个只能将数据包送达到目的地的所在的网络中,最后还是要靠 mac 地址来确定目的主机,交换机根据这个 mac 地址将数据包发送给它。 大致的流程:
- 在网络 A 中,数据包被从主机的一个网卡发出前,数据包里有目的 ip,但不知道目的地的 mac 地址,
- 主机会先根据路由表判断目标 IP 是否在本地网络,如果是本地网络,主机直接发向目标 IP 地址的 MAC 地址,如果不是本地网络,主机会将数据包发给默认网关(路由器)的 MAC 地址。
- 主机在不知道 ip 地址的 mac 地址时,通过发 arp 广播来确定,广播域中的其他主机收到广播后,如果它的 ip 是目的 ip 则响应它的 mac 地址。
- 在不是本地网络的情况,根据网关路由中的路由表把数据包给下一跳 ip。
- 层层跳转后,数据包来到了目的主机所在的网络,此时要通过交换机将这个数据包给目的主机,交换机根据 mac 地址来将数据包交给目的主机。
总结:数据包的传送最终底层还是依赖于 mac 地址,依赖于二层设备交换机。ip 地址工作在网络层,主要作用对象是工作在第三层的路由器,用来寻找目的网络,只不过听上去像是定位主机位置的感觉,其实也算是定位了吧,只不过是在网络层这个抽象的概念上的定位,类似于一个家的门牌号地址和实际的地理位置(地图上的经纬度)的区别,最终快递员还是通过地图上房子的实际位置来派送物件。
calico 的架构
各种 CNI 插件本质做的事情都差不多,改改 iptable,route tables 网络设备啥的,所以在分析 Calico 的架构之前大概也能猜得出一些:
- 每个 node 上有个进程负责维护 iptable 和网络设备,这个通过 k8s ds 可以做到。
- 有个中心化的控制组件,用于管理配置,记录路由信息等
- 可能还需要一个后端稳定的存储,如果光靠文件存储还是不太稳定,机器挂了就完蛋了。
Calico 架构图:
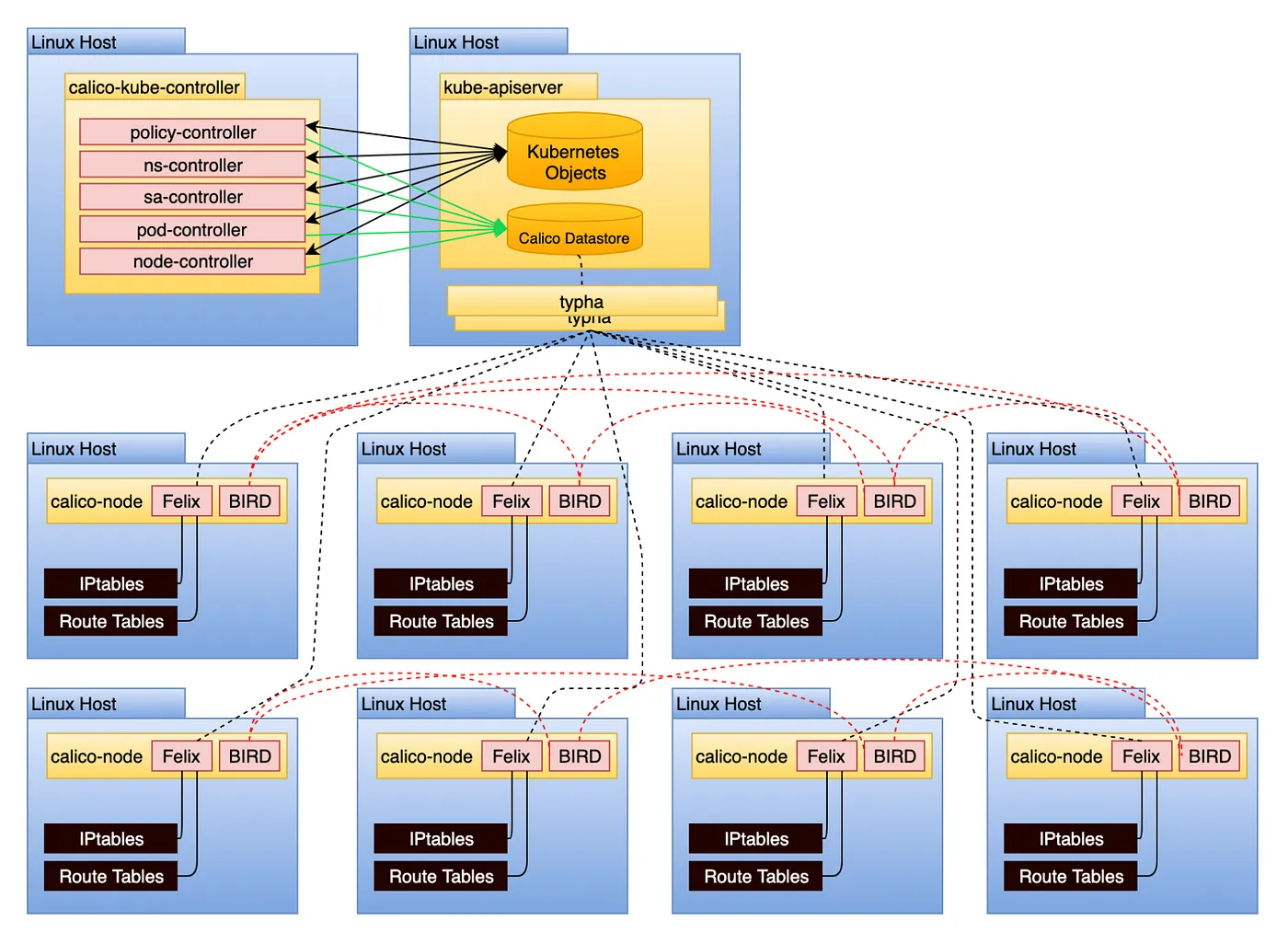 基本上和猜的差不多:
基本上和猜的差不多:
- calico-node 作为 ds 维护每个节点上的 iptable 和 route table
- calico-kube-controller 监控 k8s 资源的配置变化,作为 deployment 的 pod 部署在集群里,如果 network policy 发生变化要把这个变化推送给 calico-node 让其更改 iptable 和 route table
- Calico database 存储一些 Calico 自己的资源,不过这里应该可以通过配置将 etcd 指定为 Calico 的数据库
- typha 是可选组件,作为中间代理,减少多个 Calico 节点直接与 Kubernetes API 交互带来的负载,提高大规模集群中的同步效率
一个集群中的具体 calico 部署案例大概就是这样:
kg deploy -n kube-system | grep calico
calico-kube-controllers 1/1 1 1 324d
calico-typha 3/3 3 3 324d
kg ds -n kube-system | grep calico
calico-node 282 282 282 282 282 kubernetes.io/os=linux 297d
其中 calico-node 中有 2 个组件,他们的作用是:
- Felix:Calico 的代理(Agent),负责配置 iptables 和 路由表,实现数据包的安全策略(Network Policy)和流量转发
- BIRD:BGP 路由协议的实现,负责将节点的网络路由信息分发到其他节点,实现数据包跨节点通信
Calico 提供了多种路由模式:
- IPIP 模式(默认):Calico 会将 Pod 的 IP 流量封装成 IPIP 数据包,通过底层 Node 的 IP 地址来路由,虽然有性能损耗但是配置简单。
- VXLAN 模式:类似于 IPIP,但封装使用 VXLAN 协议。
- BGP 模式(无封装):如果底层网络能够直接路由所有 Pod 的网段,Calico 就不需要封装流量,直接使用 BGP 动态更新路由信息
pod 到宿主机的网络
可以先看这个:Calico 网络通信解析
首先在 pod 里看路由表信息:
# ip route
default via 169.254.1.1 dev eth0
169.254.1.1 dev eth0 scope link
可以看到默认网关是 169.254.1.1,169.254.1.1 保留IP地址 | IP地址 (简体中文) 🔍 是一个特殊的地址,这里 calico 将这个地址设置为 pod 的默认网关主要是让这个 ip 不与其他 ip 地址冲突。
尝试在 pod 里 traceroute 一下:
# traceroute -p 443 dev.globalad-portal.dev.jp.local
traceroute to dev.globalad-portal.dev.jp.local (100.73.3.215), 30 hops max, 46 byte packets
1 dev-node2196z.dev.jp.local (100.73.172.30) 0.005 ms 0.006 ms 0.004 ms
2 stg-fw01-jpe2-vlan2464-v.dev.jp.local (100.73.172.254) 0.164 ms 0.201 ms 0.214 ms
3 dev.globalad-portal.dev.jp.local (100.73.3.215) 0.255 ms 0.359 ms 0.277 ms
从结果来看从 pod 出发的请求下一跳是宿主机 dev-node2196z.dev.jp.local (100.73.172.30),要搞明白的是为什么到网关 169.254.1.1 的请求可以到宿主机。
Calico 会通过 veth pair 将宿主机的网卡和容器中的网卡连接,2.5.2 虚拟以太网设备 Veth | 深入架构原理与实践,首先查看宿主机的情况:
# ip link show type veth
5: calie1d6b5012fb@ens224: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether ***************** brd *****************
7: caliba9951e9d21@docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether ***************** brd *****************
571: cali5475d974730@docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether ***************** brd *****************
573: cali20a7f22e20a@docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether ***************** brd *****************
574: cali4d7f87a2695@docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether ***************** brd *****************
575: cali961628a8290@docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
.......
# ip link show type bridge
4: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether ***************** brd *****************
到 pod 里看下网络设备的情况:
# ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1
link/loopback ***************** brd *****************
2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop qlen 1
link/ipip ******* brd *******
4: eth0@if571: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether ***************** brd *****************
发现 eth0 的另一端是 if571,后面的 571 数字表示的是和宿主机的这个 calico 接口连在一起:
571: cali5475d974730@docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether ***************** brd *****************
当在 pod 中数据要被发到 169.254.1.1 时,先需要通过 arp 广播确定它的 mac 地址是什么,很明显在整个宿主机网络和容器网络里没有任何网卡的 ip 地址是 169.254.1.1,这个时候通过 calico 接口通过 proxy_arp 功能使其 ip 地址就算不是 169.254.1.1 也会响应 arp 广播并返回它 mac 地址。
确认下宿主机网卡的 proxy_arp 功能:
# cat /proc/sys/net/ipv4/conf/ens192/proxy_arp
0
# cat /proc/sys/net/ipv4/conf/ens224/proxy_arp
0
# cat /proc/sys/net/ipv4/conf/cali4449b2e925d/proxy_arp
1
# cat /proc/sys/net/ipv4/conf/cali5fff92488be/proxy_arp
1
# cat /proc/sys/net/ipv4/conf/cali5591465738e/proxy_arp
1
可以看到所有 calixxx 网卡都开启了 proxy_arp,通过这个功能从 pod 中出发的数据包就可以到宿主机上对应的 calico 网卡了。
pod 到 pod 的网络
k8s 集群中 pod 之间的通信需要知道 node 的 ip 和 pod 的 ip,实现方法有 2 种:
- 包裹原数据包,从 pod 出来的数据包只有目的 pod 的 ip, 所以要在数据包中加入源 node 和目的 node 的 ip,接收端要做额外解析,有一定的资源消耗(Flannel 的做法)。
- 直接路由实现(不需要包裹数据包),在这种方法中,Pod 到 Pod 的通信通过直接路由的方式实现,数据包不会被额外封装,而是基于主机的路由表或者 BGP(边界网关协议)来完成路由,目标 Node 和目标 Pod 的 IP 都是可以直接路由的。
Calico 实现了以上 2 种方式,可以通过 原生路由机制 实现 Pod 到 Pod 的通信,主要有以下特点:
- BGP(边界网关协议):
每个节点(Node)运行一个 BGP 客户端(如 BIRD),通过 BGP 协议将 Pod 的网络前缀(子网范围)通告给整个集群的路由表。这使得每个 Node 都知道其他 Node 上 Pod 网络的路由路径。 - 无需封装(No Encapsulation):
数据包直接基于路由表从源 Pod 发送到目标 Pod,不需要封装成 IPIP、VXLAN 等隧道形式。这避免了封装带来的资源消耗,提高了网络性能。 - 路由表更新:
当 Pod 网络发生变更(比如新 Pod 部署或删除)时,Calico 的组件(如 Felix 和 BGP Daemon)动态更新路由表,确保路由信息是最新的。 - 多种数据存储选项:
Calico 可以使用 Kubernetes API Server 作为配置数据存储,也可以使用 etcd 来存储网络策略和路由信息。 Calico 的直接路由实现网络性能更高,尤其在大规模集群场景下更为高效,但需要配置和维护路由信息(通常借助 BGP)。
接下来去公司的集群里验证下 Calico 的实现。
看下集群中一个 node 的 ip 和这个 node 上运行的一个 pod 的 ip:
node A ip: 100.119.66.41
pod1 ip: 100.86.153.153
在另一个节点 node B 上查看路由信息
# node B ip: 100.99.66.15
# ip route | grep 100.86.153
100.86.153.128/27 via 100.119.66.41 dev tunl0 proto bird onlink
100.86.153.192/27 via 100.99.69.62 dev tunl0 proto bird onlink
node A 上的 pod1 的 100.86.153.153 在 100.86.153.128/27 这个网段里,node B 根据本机路由表的配置就知道往 pod1 的网络的下一个路由目标是 100.119.66.41,即 node A 的 ip,而在 node A 上的路由表 Calico 也配置了往 pod1 的路由是 cali9cc5c053625:
# ip route | grep 100.86.153.153
100.86.153.153 dev cali9cc5c053625 scope link
cali9cc5c053625 连着容器端的网卡,从而将数据路由给了 pod1。
传输流程是: Pod-1 -> calixxx -> tunl0 -> eth0 <—-> eth0 -> tunl0 -> calixxx -> Pod-2
分析到这里突然的一个疑问是,关于 node 的 ip 分配是怎么做的?公司里的 node 的网络是通过使用 network team 创建的 subnet 来分配 ip 的,不是 calico 来分配的 ip,这属于是 k8s 集群范围外的事情,那么 calico 是怎么感知这种的 node ip 的变化从而维护整个路由信息的呢?在上面的 node A 和 node B 的 ip 地址分别是 100.119.66.41 和 100.99.66.15,属于是 2 个不同的 subnet,这种跨 subnet 的路由需要走路由器来中转吗?
思考了下,我的回答是这样的:
- Node 的 IP 来源:calico 作为 cni 插件,负责的是分配 pod 的 ip,不是 node 的 ip,node 的 IP 是 Kubernetes 集群外部的事情(例如 DHCP、静态配置,或通过公司 Network Team 的分配)
- Node 的 IP 感知:Calico 通过 Kubernetes 的 API 自动发现 Node 的 IP 地址,从而维护全局的路由表。
- 同一集群中跨 subnet 访问:需要底层路由器支持,公司的扁平化网络肯定是一个数据中心内所有机器都通过交换机和路由互通的,网络限制通过软件层面(如 ACL)来做的,每次有新的 node 用新的 subnet 时,直接加入集群里就行了,不用考虑路由器设置问题(network team 在创建新的 network 时应该都已经弄好了)。
给了 AI 看上面的路由信息:
100.86.153.128/27 via 100.119.66.41 dev tunl0 proto bird onlink
AI 根据 dev tunl0 判断 Calico 是 IPIP 模式,但是从路由信息来看不是纯路由实现的么?应该是 BGP 模式(无封装)才对啊,有点混乱。
查看集群中的 calico 的工作模式:
calicoctl --allow-version-mismatch get ippool -o yaml
apiVersion: projectcalico.org/v3
items:
- apiVersion: projectcalico.org/v3
kind: IPPool
metadata:
creationTimestamp: "2024-07-29T06:03:57Z"
name: default-ipv4-ippool
resourceVersion: "2330"
uid: a28320ff-d143-48a4-b6a0-91e37279a47a
spec:
allowedUses:
- Workload
- Tunnel
blockSize: 27
cidr: 100.86.0.0/16
ipipMode: Always
natOutgoing: true
nodeSelector: all()
vxlanMode: Never
kind: IPPoolList
metadata:
resourceVersion: "742363428"
可以看到 ipipMode 配置为了 Always,即的确是用 IPIP 模式…..,又是日常被 Ai 吊打的一天。
也就是说,无论 Calico 是哪种模式(纯路由模式或 IPIP/VXLAN 模式),都需要通过 BGP 来维护每个节点上 Pod 网络的路由信息。然而,是否需要在数据包中封装额外的 Node 的 IP 地址,则取决于底层网络的能力:
- 底层网络支持跨子网直接通信:
如果底层网络能够支持不同子网的节点之间直接通信,那么 Calico 可以采用纯路由模式。这种情况下,数据包的目的 IP 就是目标 Pod 的 IP,而路由表中会直接指向目标节点的 IP,不需要额外的封装。 - 底层网络不支持跨子网直接通信:
如果底层网络无法直接跨子网通信(例如,某些云平台或复杂的网络环境中),Calico 则需要启用 IPIP 或 VXLAN 模式。这种情况下,数据包在发送时会封装额外的 Header(如源 Node 的 IP 和目标 Node 的 IP),以确保数据包能够通过底层网络正确传递到目标节点。
因此,Calico 的工作模式会根据网络的需求动态调整。在支持直接路由的环境中,纯路由模式效率更高,而在复杂网络中,隧道模式则是必要的补充